
Op-ed: Planetary impacts, escalating financial costs, and labor exploitation all factor.

Dr. Sasha Luccioni is a Researcher and Climate Lead at Hugging Face, where she studies the ethical and societal impacts of AI models and datasets. She is also a director of Women in Machine Learning (WiML), a founding member of Climate Change AI (CCAI), and chair of the NeurIPS Code of Ethics committee. The opinions in this piece do not necessarily reflect the views of Ars Technica.
Over the past few months, the field of artificial intelligence has seen rapid growth, with wave after wave of new models like Dall-E and GPT-4 emerging one after another. Every week brings the promise of new and exciting models, products, and tools. It’s easy to get swept up in the waves of hype, but these shiny capabilities come at a real cost to society and the planet.
Downsides include the environmental toll of mining rare minerals, the human costs of the labor-intensive process of data annotation, and the escalating financial investment required to train AI models as they incorporate more parameters.
Let’s look at the innovations that have fueled recent generations of these models—and raised their associated costs.
Bigger models
In recent years, AI models have been getting bigger, with researchers now measuring their size in the hundreds of billions of parameters. “Parameters” are the internal connections used within the models to learn patterns based on the training data.
For large language models (LLMs) like ChatGPT, we’ve gone from around 100 million parameters in 2018 to 500 billion in 2023 with Google’s PaLM model. The theory behind this growth is that models with more parameters should have better performance, even on tasks they were not initially trained on, although this hypothesis remains unproven.
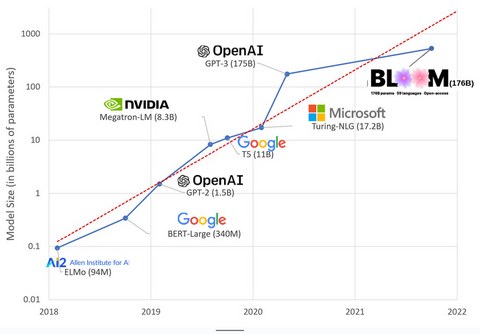
Bigger models typically take longer to train, which means they also need more GPUs, which cost more money, so only a select few organizations are able to train them. Estimates put the training cost of GPT-3, which has 175 billion parameters, at $4.6 million—out of reach for the majority of companies and organizations. (It's worth noting that the cost of training models is dropping in some cases, such as in the case of LLaMA, the recent model trained by Meta.)
This creates a digital divide in the AI community between those who can train the most cutting-edge LLMs (mostly Big Tech companies and rich institutions in the Global North) and those who can’t (nonprofit organizations, startups, and anyone without access to a supercomputer or millions in cloud credits). Building and deploying these behemoths requires a lot of planetary resources: rare metals for manufacturing GPUs, water to cool huge data centers, energy to keep those data centers running 24/7 on a planetary scale… all of these are often overlooked in favor of focusing on the future potential of the resulting models.
Planetary impacts
A study from Carnegie Melon University professor Emma Strubell about the carbon footprint of training LLMs estimated that training a 2019 model called BERT, which has only 213 million parameters, emitted 280 metric tons of carbon emissions, roughly equivalent to the emissions from five cars over their lifetimes. Since then, models have grown and hardware has become more efficient, so where are we now?
In a recent academic article I wrote to study the carbon emissions incurred by training BLOOM, a 176-billion parameter language model, we compared the power consumption and ensuing carbon emissions of several LLMs, all of which came out in the last few years. The goal of the comparison was to get an idea of the scale of emissions of different sizes of LLMs and what impacts them.
The current trend is toward creating bigger and more closed and opaque models. But there’s still time to push back, demand transparency, and get a better understanding of the costs and impacts of LLMs while limiting how they are deployed in society at large. Legislation like the Algorithmic Accountability Act in the US and legal frameworks on AI governance in the European Union and Canada are defining our AI future and putting safeguards in place to ensure safety and accountability in future generations of AI systems deployed in society. As members of that society and users of these systems, we should have our voices heard by their creators.
Dr. Sasha Luccioni is a Researcher and Climate Lead at Hugging Face, where she studies the ethical and societal impacts of AI models and datasets. She is also a director of Women in Machine Learning (WiML), a founding member of Climate Change AI (CCAI), and chair of the NeurIPS Code of Ethics committee.
By: Sacha Luccione - Ars Technica 04/12/2023