
Tribune : Les impacts planétaires, l’escalade des coûts financiers et l’exploitation du travail sont autant de facteurs qui entrent en jeu.

Dr. Sasha Luccioni est chercheuse et responsable du climat chez Hugging Face, où elle étudie les impacts éthiques et sociétaux des modèles et des ensembles de données d'IA. Elle est également directrice de Women in Machine Learning (WiML), membre fondatrice de Climate Change AI (CCAI) et présidente du comité du code d'éthique de NeurIPS. Les opinions exprimées dans cet article ne reflètent pas nécessairement celles d'Ars Technica.
Au cours des derniers mois, le domaine de l'intelligence artificielle a connu une croissance rapide, avec l'émergence de nouveaux modèles comme Dall-E et GPT-4. Chaque semaine apporte son lot de promesses de nouveaux modèles, produits et outils passionnants. Il est facile de se laisser emporter par le battage médiatique, mais ces capacités brillantes ont un coût réel pour la société et la planète.
Les inconvénients incluent le coût environnemental de l’extraction de minéraux rares, les coûts humains du processus d’annotation des données, qui nécessite beaucoup de travail, et l’investissement financier croissant nécessaire pour former les modèles d’IA à mesure qu’ils intègrent davantage de paramètres.
Examinons les innovations qui ont alimenté les récentes générations de ces modèles et augmenté les coûts qui leur sont associés.
Modèles plus grands
Ces dernières années, les modèles d’IA sont devenus de plus en plus volumineux, les chercheurs mesurant désormais leur taille en centaines de milliards de paramètres. Les « paramètres » sont les connexions internes utilisées dans les modèles pour apprendre des modèles basés sur les données d’entraînement.
Pour les grands modèles de langage (LLM) comme ChatGPT, on est passé d'environ 100 millions de paramètres en 2018 à 500 milliards en 2023 avec le modèle PaLM de Google. La théorie derrière cette croissance est que les modèles avec plus de paramètres devraient avoir de meilleures performances, même sur des tâches sur lesquelles ils n'ont pas été initialement entraînés, bien que cette hypothèse reste à prouver .
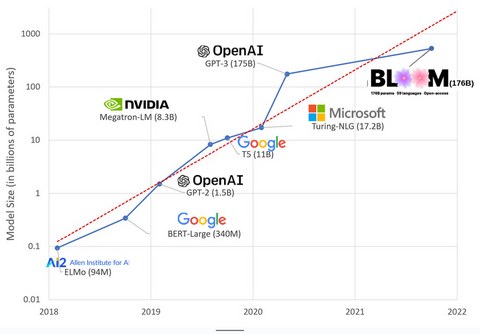
Les modèles plus volumineux prennent généralement plus de temps à former, ce qui signifie qu'ils nécessitent également plus de GPU, ce qui coûte plus cher, et seules quelques organisations sont en mesure de les former. Selon les estimations, le coût de formation de GPT-3, qui compte 175 milliards de paramètres, s'élève à 4,6 millions de dollars, ce qui est hors de portée de la majorité des entreprises et organisations. (Il convient de noter que le coût de formation des modèlesdiminue dans certains cas , comme dans le cas de LLaMA, le récent modèle formé par Meta.)
Cela crée une fracture numérique au sein de la communauté de l’IA entre ceux qui peuvent former les LLM les plus pointus (principalement les grandes entreprises technologiques et les institutions riches du Nord global) et ceux qui ne le peuvent pas (les organisations à but non lucratif, les startups et toute personne n’ayant pas accès à un supercalculateur ou à des millions de crédits cloud). La construction et le déploiement de ces mastodontes nécessitent de nombreuses ressources planétaires : des métaux rares pour la fabrication des GPU, de l’eau pour refroidir d’énormes centres de données, de l’énergie pour faire fonctionner ces centres de données 24 heures sur 24 et 7 jours sur 7 à l’échelle planétaire… tous ces éléments sont souvent négligés au profit de la concentration sur le potentiel futur des modèles qui en résultent.
Impacts planétaires
Une étude d’ Emma Strubell, professeure à l’université Carnegie Melon, sur l’empreinte carbone de la formation des LLM a estimé que la formation d’un modèle de 2019 appelé BERT, qui ne compte que 213 millions de paramètres, a émis 280 tonnes métriques d’émissions de carbone, soit à peu près l’équivalent des émissions de cinq voitures au cours de leur durée de vie. Depuis lors, les modèles ont évolué et le matériel est devenu plus efficace, alors où en sommes-nous aujourd’hui ?
Dans un article universitaire récent que j'ai écrit pour étudier les émissions de carbone induites par l'entraînement de BLOOM, un modèle de langage à 176 milliards de paramètres, nous avons comparé la consommation d'énergie et les émissions de carbone qui en découlent de plusieurs LLM, tous sortis au cours des dernières années. L'objectif de la comparaison était d'avoir une idée de l'ampleur des émissions de différentes tailles de LLM et de ce qui les impacte.
La tendance actuelle est à la création de modèles plus grands, plus fermés et plus opaques. Mais il est encore temps de réagir, d’exiger de la transparence et de mieux comprendre les coûts et les impacts des LLM tout en limitant la manière dont ils sont déployés dans la société en général. Des lois telles que l’ Algorithmic Accountability Act aux États-Unis et les cadres juridiques sur la gouvernance de l’IA dans l’ Union européenne et au Canada définissent notre avenir en matière d’IA et mettent en place des garde-fous pour assurer la sécurité et la responsabilité des futures générations de systèmes d’IA déployés dans la société. En tant que membres de cette société et utilisateurs de ces systèmes, nous devons faire entendre notre voix auprès de leurs créateurs.
Dr. Sasha Luccioni est chercheuse et responsable du climat chez Hugging Face, où elle étudie les impacts éthiques et sociétaux des modèles et des ensembles de données d'IA. Elle est également directrice de Women in Machine Learning (WiML), membre fondatrice de Climate Change AI (CCAI) et présidente du comité du code d'éthique de NeurIPS.
Par : Sacha Luccione - Ars Technica 12/04/2023